2020 Sep 21 Statistics and Biostatistics Colloquium: Xihong Lin (Harvard University) 10:30am to 11:30am Location: Zoom - please contact emilie_campanelli@fas.harvard.edu for more information Title: Learning from COVID-19 Data in Wuhan, USA and the World on Transmission, Health Outcomes and Interventions Abstract: ... Read more about Statistics and Biostatistics Colloquium: Xihong Lin (Harvard University)
2020 Sep 14 Statistics Colloquium: Pragya Sur (Harvard University) 10:30am to 11:30am Location: Zoom - please contact emilie_campanelli@fas.harvard.edu for more information Title: A precise high-dimensional theory for Boosting Abstract: ... Read more about Statistics Colloquium: Pragya Sur (Harvard University)
2020 Apr 27 (POSTPONED until further notice) Statistics Colloquium: Jeff Miller (Harvard) 12:00pm to 1:00pm Location: Science Center, Hall EPostponed until further notice.
2020 Apr 20 (POSTPONED until further notice) Statistics Colloquium: Jelena Bradic (UC-San Diego) 12:00pm to 1:00pm Location: Science Center, Hall EPostponed until further notice.
2020 Apr 06 (POSTPONED until further notice) Statistics Colloquium: Genevera Allen (Rice) 12:00pm to 1:00pm Location: Science Center, Hall EPostponed until further notice.
2020 Mar 30 (POSTPONED until further notice) Statistics Colloquium: Frauke Kreuter (University of Maryland) 12:00pm to 1:00pm Location: Science Center, Hall EPostponed until further notice.
2020 Mar 23 (POSTPONED until further notice) Statistics Colloquium: Peng Ding (UC-Berkeley) 12:00pm to 1:00pm Location: Science Center, Hall EPostponed until further notice.
2020 Mar 09 Statistics Colloquium: Daniel Roy (University of Toronto) 12:00pm to 1:00pm Location: Science Center, Hall E Title: Generalization via derandomization with an application to interpolating predictors Abstract: In this talk, I discuss the challenge of understanding the statistical properties of modern... Read more about Statistics Colloquium: Daniel Roy (University of Toronto)
2020 Mar 02 Statistics Colloquium: Yue Lu (Harvard) 12:00pm to 1:00pm Location: Science Center, Hall E Title: Asymptotic Methods... Read more about Statistics Colloquium: Yue Lu (Harvard)
2020 Feb 24 Statistics Colloquium: Philippe Rigollet (MIT) 12:00pm to 1:00pm Location: Science Center, Hall E Title: Statistical and Computational Aspects of Wasserstein Barycenters Abstract: The notion of average is central to most statistical methods. In... Read more about Statistics Colloquium: Philippe Rigollet (MIT)
 Title:
Title:
 Title:
Title:
 Title:
Title:
 Title:
Title:
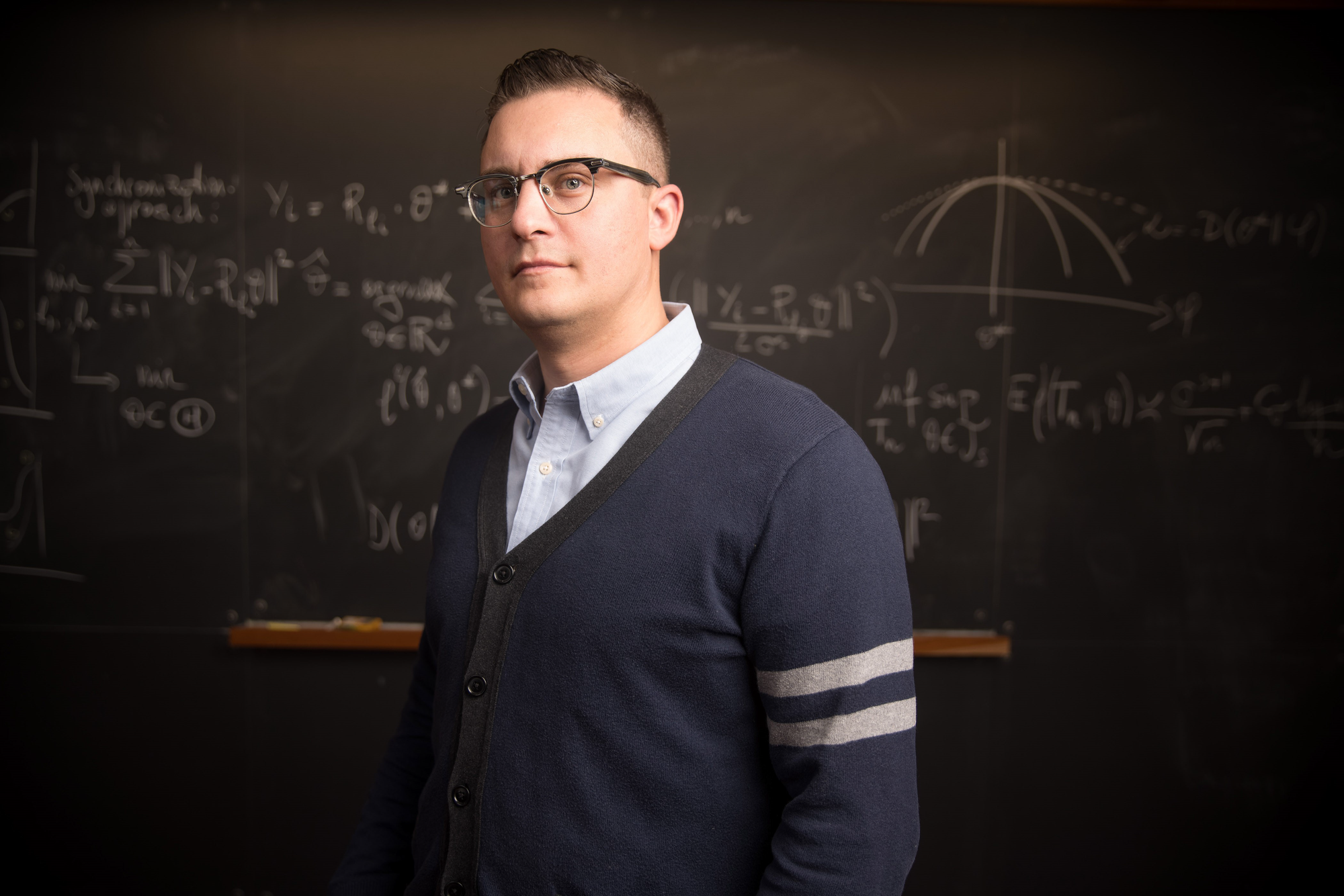 Title:
Title: